Abstract
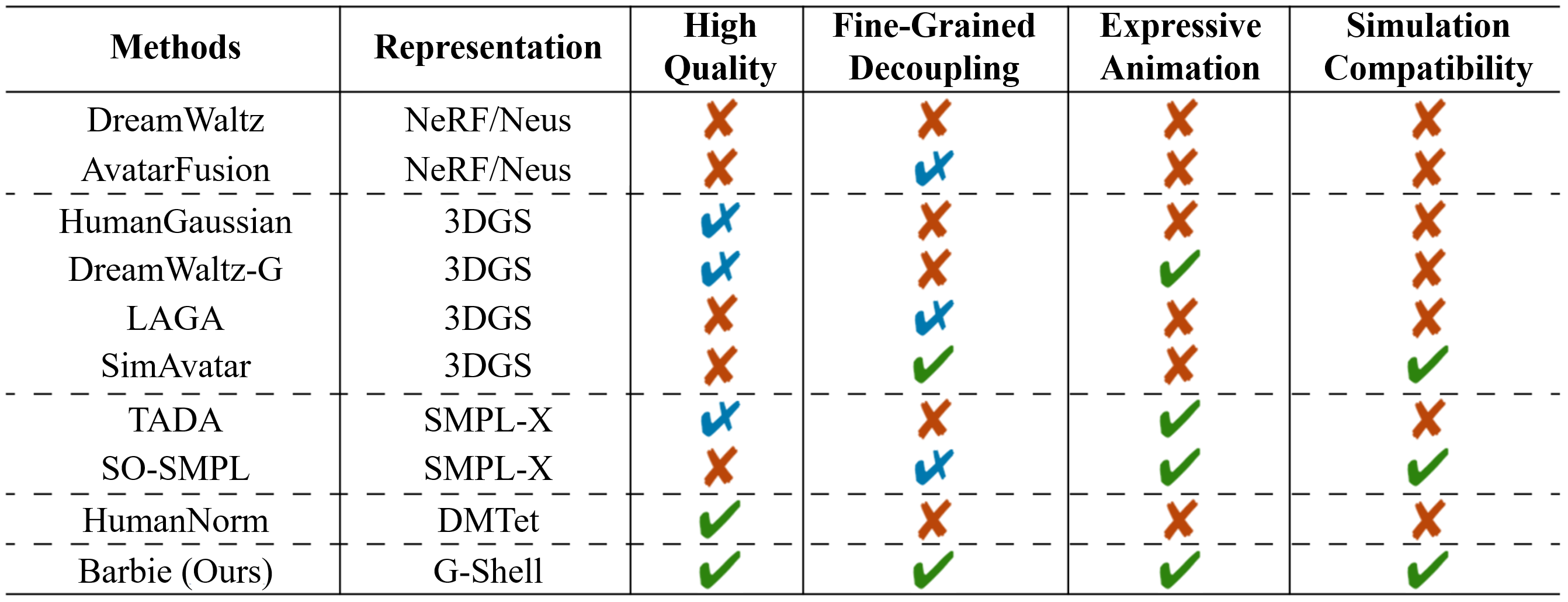
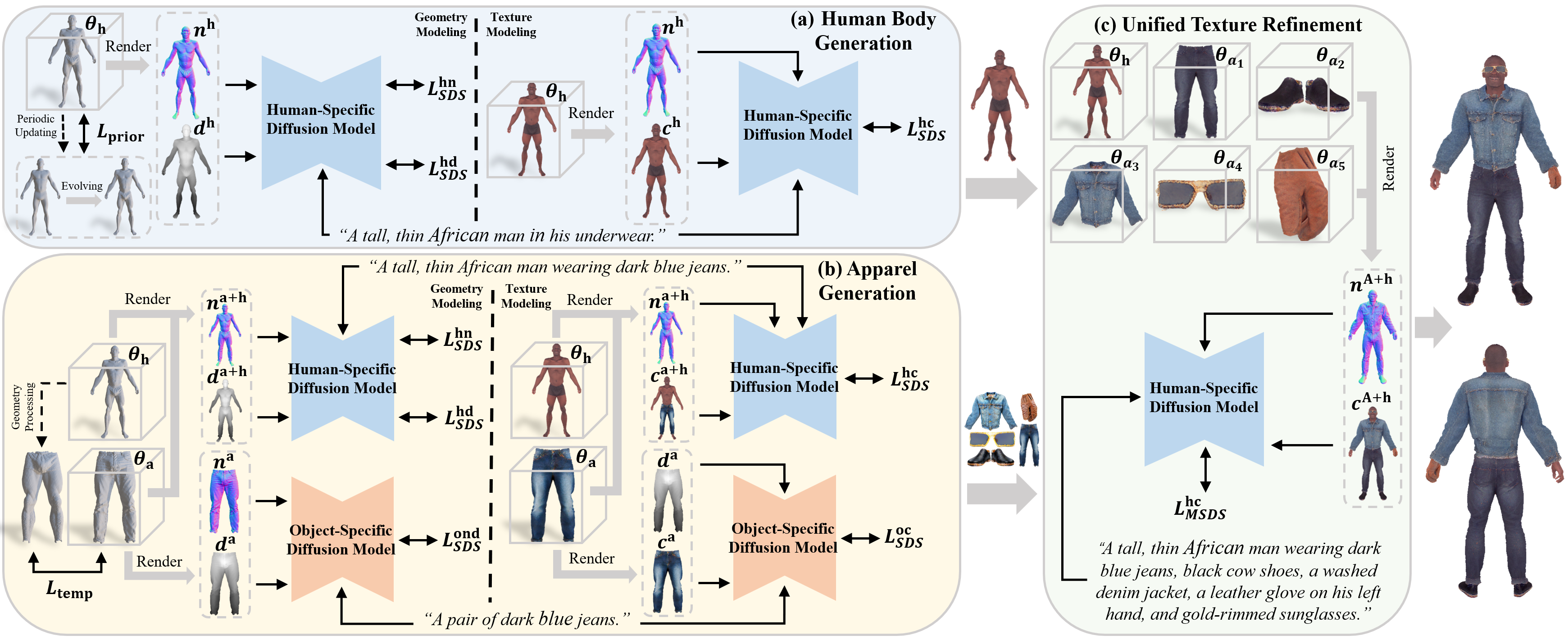
To integrate digital humans into everyday life, there is a strong demand for generating high-quality, fine-grained disentangled 3D avatars that support expressive animation and simulation capabilities, ideally from low-cost textual inputs. Although text-driven 3D avatar generation has made significant progress by leveraging 2D generative priors, existing methods still struggle to fulfill all these requirements simultaneously. To address this challenge, we propose Barbie, a novel text-driven framework for generating animatable 3D avatars with separable shoes, accessories, and simulation-ready garments, truly capturing the iconic ``Barbie doll'' aesthetic. The core of our framework lies in an expressive 3D representation combined with appropriate modeling constraints. Unlike previous methods, we innovatively employ G-Shell to uniformly model both watertight components (e.g., bodies, shoes, and accessories) and non-watertight garments compatible with simulation. Furthermore, we introduce a well-designed initialization and a hole regularization loss to ensure clean open surface modeling. These disentangled 3D representations are then optimized by specialized expert diffusion models tailored to each domain, ensuring high-fidelity outputs. To mitigate geometric artifacts and texture conflicts when combining different expert models, we further propose several effective geometric losses and strategies. Extensive experiments demonstrate that Barbie outperforms existing methods in both dressed human and outfit generation. Our framework further enables diverse applications, including apparel combination, editing, expressive animation, and physical simulation.